
Check our new Guide
Learn how to partner with the right sportsbook provider and start your betting business with confidence.
Start reading
In the bustling tech landscape of GR8 Tech, Kafka reigns supreme as the linchpin, facilitating seamless communication between our microservices. As a message weaves through our system, it might navigate multiple services, each sculpting, enhancing, or rerouting it across various topics. These services, stewarded by diverse teams, underscore the importance of unraveling the intricate details within each message. This becomes all the more crucial when our workflows hit an unexpected roadblock. On the surface, the remedy might appear straightforward: retrieve and examine the pertinent Kafka messages. Yet, as always, the nuances offer the most enlightening revelations.
At its core, Kafka transcends its commonly perceived role as a mere message broker. It epitomizes a distributed log system. While this embodies myriad facets, what’s intriguing to us is its capability to retain messages post-delivery. These messages, thus, are ever-accessible for subsequent reads and introspection. This presents a complexity, however, given Kafka’s design, which facilitates only sequential reading. Hence, pinpointing a message’s ‘offset’ (essentially its sequence in a topic) becomes crucial. While initiating reads based on a timestamp is feasible, the read-out remains inherently sequential.
Imagine the task of troubleshooting an issue linked to a player bearing the id=42. The daunting challenge lies in meticulously combing through a mountain of messages, identifying all pertaining to this player, and methodically piecing together the narrative to detect the anomaly.
While popular databases like MySQL or MSSQL pamper users with intuitive GUI clients, Kafka adopts a spartan approach, primarily offering command-line utilities. To a newbie, these might appear somewhat restrictive.
However, the horizon isn’t devoid of silver linings. A slew of tools, generously available for free, have emerged to demystify this complex Kafka journey.
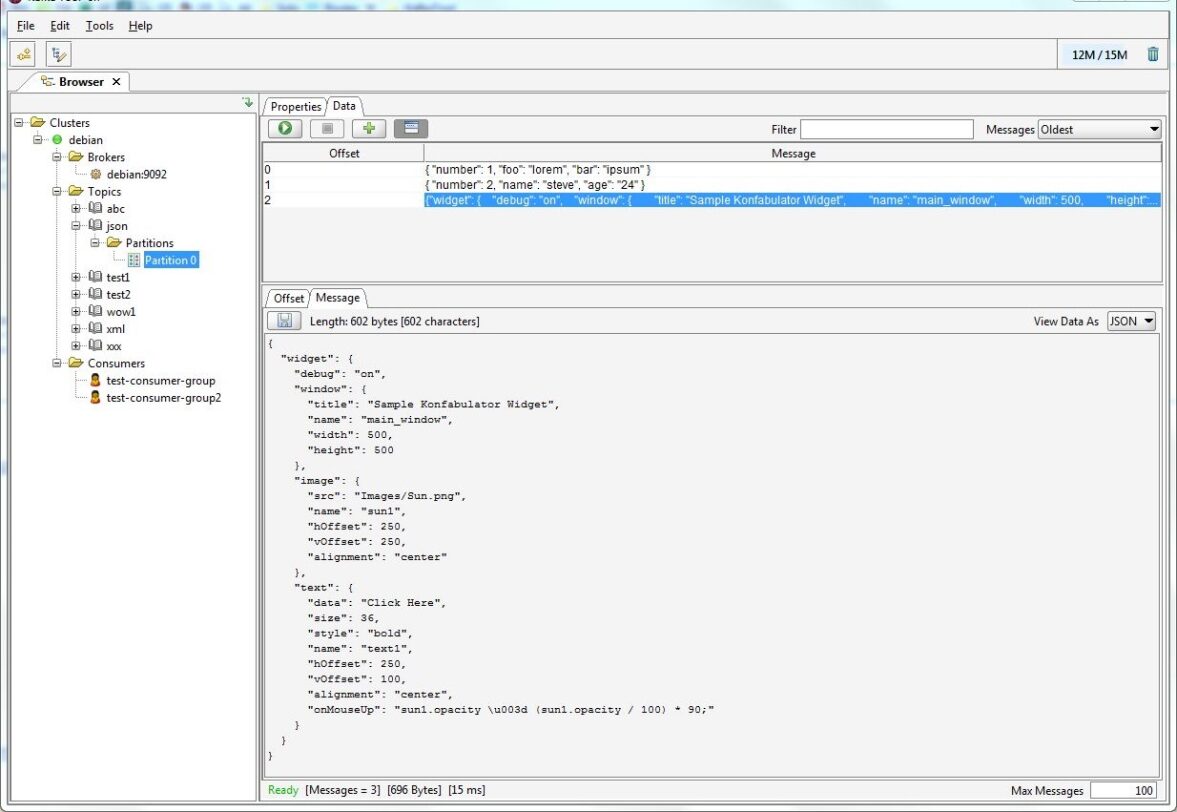
Kafka Tool: A cherished ally for those with a penchant for GUI-based platforms. It unveils a directory of topics and facilitates individual message inspection. Features like content-filtering, offset-determination, and read-count specification augment its utility. A word of caution, though a ballpark understanding of the desired message offsets remains pivotal, given that Kafka Tool’s scope remains bound by the messages ingested.
For a majority, especially those inadvertently navigating the Kafka labyrinth, Kafka Tool emerges as their default beacon. Nonetheless, a repertoire of equally robust alternatives beckons exploration.
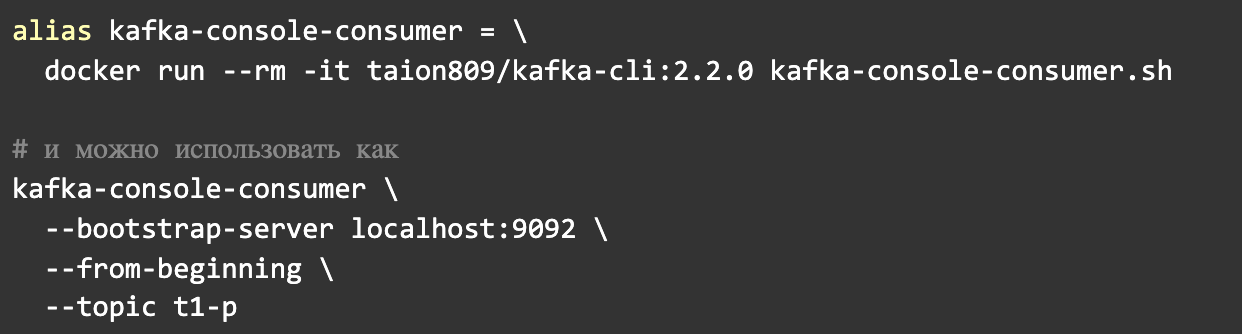
Kafka Console Consumer is one of the native utilities packaged with Kafka, designed specifically for reading data. Being a JVM application, it mandates the presence of Java for its smooth operation. This Java dependency holds true for the Kafka Tool as well, but with a twist: those leveraging Docker can bypass this Java prerequisite.

To elucidate, all one needs to do is prefix their command with `docker run — rm -it taion809/kafka-cli:2.2.0`. In Docker lingo, this translates to: “execute this image, mirror its output on my screen, and upon completion, discard the image.” To streamline this process further, consider crafting an alias.
Enter Kafkacat—a robust utility designed for interacting with Kafka. At the same time, it’s console-based, much like the Kafka-console-consumer. Its intuitive nature makes it notably more user-friendly. For those accustomed to the Kafka ecosystem, think of Kafkacat as the Kafka-console-consumer’s evolved sibling (though both can be orchestrated via Docker).
Here’s a simple illustration: To archive 10 messages into a file (formatted in JSON), one can utilize Kafkacat for this precise task. While traditional consumers can achieve this, Kafkacat’s brevity makes the process more efficient.

Digging deeper, let’s explore a slightly intricate example inspired by the insights of Robin Moffatt, a prominent advocate of the Kafka realm. In this instance, one Kafkacat session retrieves messages from a Kafka topic. Post-transformation messages into a desired format are channeled into another Kafkacat session, which then archives them into a different topic. To the uninitiated, this might seem like it could be clearer. However, what we have is a plug-and-play solution optimized for Docker. Attempting a similar implementation using platforms like Dotnet or Java would invariably be more verbose.
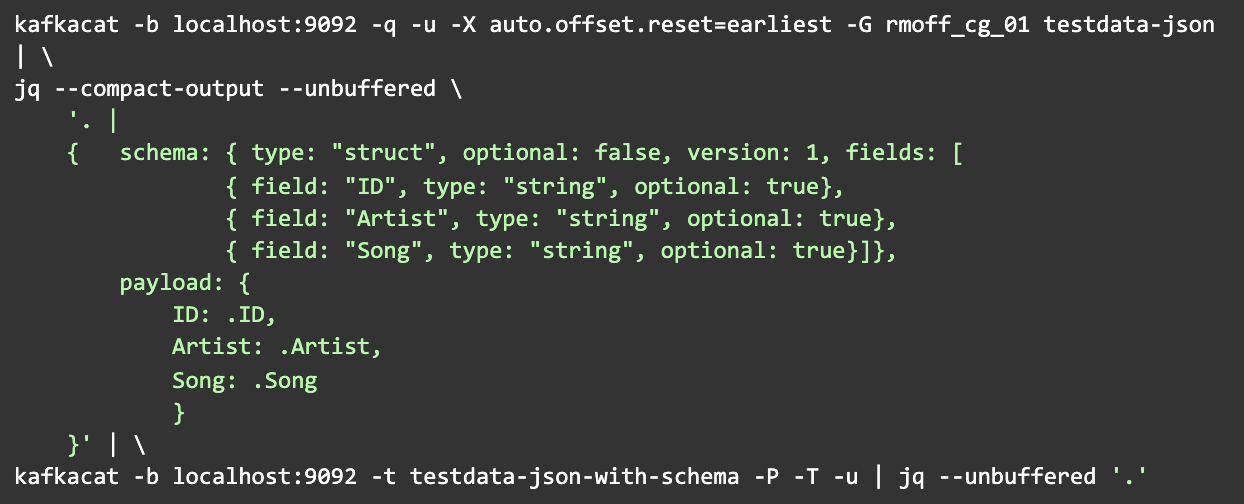
But let’s refocus on our primary theme: message searching. With Kafkacat, streamlining a search is uncomplicated. Simply channel the output into a grep tool, and voila!
While Kafkacat is commendably versatile, there’s always room for enhancement. A notable advantage is its native support for Avro. However, it’s worth noting that, as of now, Kafkacat doesn’t inherently support Protobuf.
While various tools and techniques provide functionality for Kafka, not all are user-friendly or intuitive, especially when searching across topics for specific text elements. Our Quality Assurance (QA) team, often tasked with such investigations, previously toggled between Kafka Tool and console utilities. However, these methods seemed rudimentary when pitted against the prowess of Kibana—a graphical interface for the Elasticsearch database, which our QA also employed for log analysis.
The recurring proposition was straightforward: “Why not log all messages for a seamless Kibana search experience?” But instead of injecting a logger into each service, we found a more streamlined approach in Kafka Connect.
Kafka Connect serves as a bridge linking Kafka with various systems. Simply put, it facilitates the hassle-free import and export of data to and from Kafka, requiring zero code. You just need a functional Connect cluster and your configurations articulated in JSON. The term “cluster” might evoke images of intricate setups, but in reality, it’s just one or multiple instances—something we’ve seamlessly integrated within our Kubernetes alongside regular services.
To manage connectors interfacing with Kafka, Kafka Connect presents a REST API. Through configurations like the one for Elasticsearch, you can easily direct data flow:

If such config is sent via HTTP PUT to the Connect server, then, under a certain set of circumstances, a connector named ElasticSinkConnector will be created, which will read data from the topic in three threads and write it to Elastic.
Everything looks very simple, but the most interesting thing, of course, is in the details.
Most of the problems are data-related. Usually, as in our case, you need to work with data formats, the developers of which obviously did not think that someday this data would end up in Elasticsearch.
There are transformations to solve nuances with data. These are functions that can be applied to data and mutated, adjusting to the requirements of the recipient. At the same time, it is always possible to use any Kafka client technology for cases when transformations are powerless. What scenarios were we solving with the help of transformations?
In our case, there are 4 transformations. We list them first and then configure them. Transformations are applied in the order they are listed, and this allows you to combine them in an interesting way.
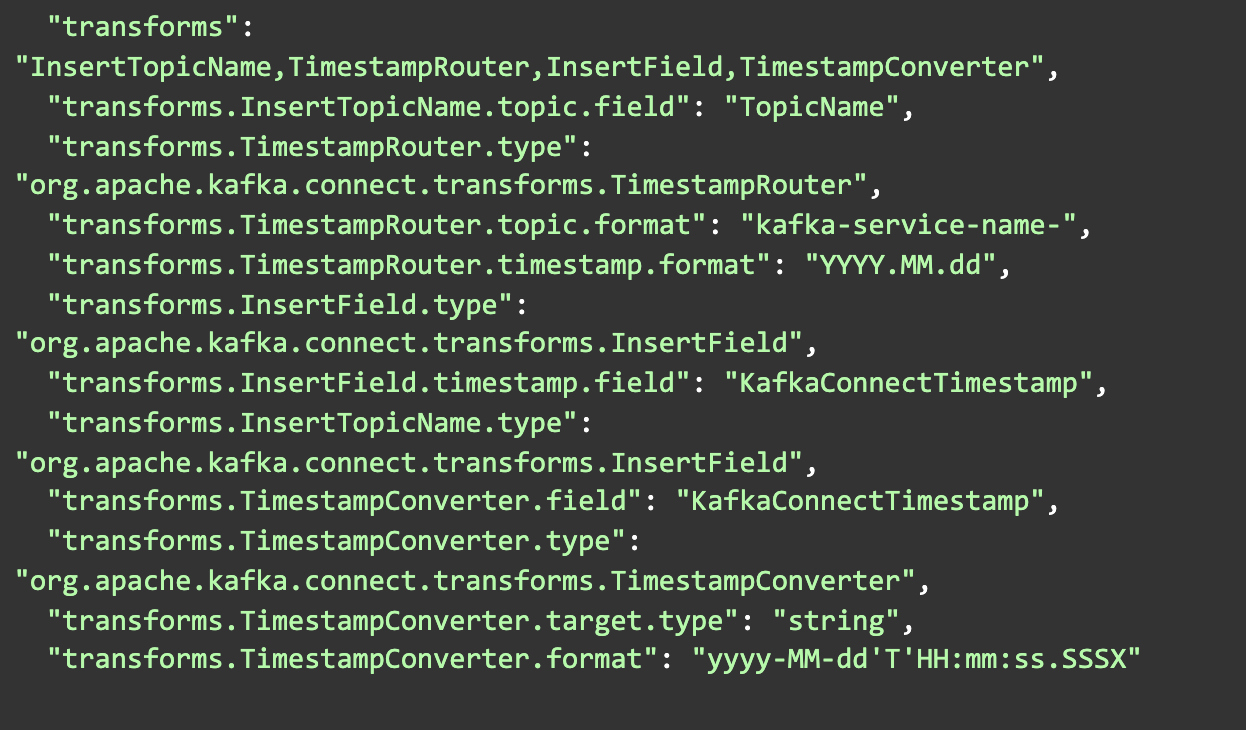
Managing data is where challenges lurk. Often, data formats aren’t inherently tailored for Elasticsearch compatibility. To circumvent such issues, we employ transformations—functions refining data to meet the destination’s criteria. However, for trickier situations, any Kafka client technology can be leveraged.

The resultant process expedited data analysis, drastically reducing incident assessment time. Although this approach is still being integrated, the vision is clear: a comprehensive Kibana search experience.
Broadly, Kafka Connect isn’t restricted to just these applications. It’s a versatile tool, ideal for system integrations. Envisage enhancing your application with a full-text search: utilize two connectors—one to funnel database updates to Kafka and the other to channel data from Kafka to Elasticsearch. Your application can then query Elasticsearch, retrieve an ID, and pinpoint the data in the primary database.
I hope this exploration has added a fresh perspective or knowledge to your arsenal. After all, the objective was to enlighten and share! I’m all ears if you’ve encountered any hitches, have a differing viewpoint, or believe there’s a more efficient solution to any discussed problem. Let’s engage in a fruitful discussion.
By Sergey Kalinets, Solutions Architect at GR8 Tech
GR8 Tech promotes responsible gambling. The content on this website is intended solely for B2B industry professionals and individuals who have reached the minimum age required for online gambling in their jurisdiction.















