Bootstrap Servers
Let’s commence with the very beginning—the Kafka connect aspect. When establishing a connection to Kafka, specifying bootstrap servers is essential. Typically, you’d receive a list of addresses for all the brokers within the cluster. However, it’s sufficient to specify just a subset of these addresses; in some cases, even one could suffice.
Now, why is this the case? To unravel this, let’s delve into how clients connect to Kafka. When a client initiates a connection, it specifies both the topic and its partition (more on partitions later). To begin writing to or reading from that partition, the client must connect to its leader, and it’s important to note that the leader is always one of the cluster’s brokers. Fortunately, Kafka’s creators have made the process developer-friendly by eliminating the need for us to search for a leader manually. The client can connect to any broker, and that broker will then re-route the connection to the leader of the requested partition.
This means that for a successful connection to the cluster, knowing the address of just one broker is sufficient. So, why bother specifying the entire list? The list of addresses is crucial in enhancing the cluster’s availability, especially when some brokers are unavailable. The client sequentially connects to the brokers on the list until it receives a response.
💡 For local development and testing purposes, a single address is typically adequate. However, specifying three addresses is a reasonable approach to production. In such scenarios, the system continues to function seamlessly even if two brokers face unavailability—a highly exceptional situation. While it’s possible to list all brokers, it’s worth noting that brokers may be added or removed by cluster operators. Consequently, maintaining a comprehensive broker list could result in unnecessary administrative overhead.
Retention
Kafka presents an intriguing paradox—it appears deceptively simple yet complex. At its core, it’s a service that facilitates the reading and writing of bytes. However, beneath this simplicity lies a myriad of settings governing the transmission and storage of these bytes.
Take, for instance, the ability to define how long messages should linger on a topic. Unlike conventional message brokers that merely transmit data, Kafka goes further by storing it. In essence, Kafka operates as a commit log, a structure where data is exclusively appended to the end. Once Kafka acknowledges receipt of a message, it retains it for as long as specified.
This is where retention settings come into play, shaping the “as long as required” aspect. You can configure messages for deletion based on various criteria, whether a designated period or a predefined size threshold.
Here’s where it gets intriguing—deletions aren’t instantaneous; instead, Kafka makes this call. Due to specific technical intricacies, eligible messages might persist even after the cleanup process has been executed. Why is this the case? Kafka organizes data into files known as “segments.” There can be multiple segments for a given partition, with one designated as the “active” segment where new data is written. When this active segment reaches a certain size or age, it transitions into an inactive state, and a fresh active segment occurs. Cleanup operations exclusively target data in these inactive segments. Therefore, when you set a retention period, such as one day, but the segment settings remain at their defaults (requiring a week’s lifespan or reaching a gigabyte in size for inactivity), it’s plausible that aged data remains intact, leading to perplexity.
We’ve encountered similar disconcerting scenarios when configuring topic retention for two weeks, only to realize, during some recovery process, that revisiting the topics from the outset unexpectedly led to the reprocessing of old data.
💡 Hence, the golden rule is to exercise caution and refrain from relying on Kafka’s data retention settings within your business logic. They simply do not provide any ironclad guarantees.
Kafka Log Compaction
In addition to the standard deletion process, Kafka introduces a concept known as compaction – a method wherein Kafka removes aging messages and erases all preceding messages sharing identical keys (we’ll delve deeper into keys shortly). Notably, even messages located within the middle segment of the topic are subject to removal. But why is this nuanced approach necessary?
Compaction serves a crucial role in optimizing storage space by eliminating data that has become redundant. Retaining previous versions is no longer necessary when we modify an entity and create snapshots, encapsulating the current state following each change. The most recent snapshot suffices. Therefore, compaction primarily revolves around the elimination of these prior iterations.
Topics employing compaction can be likened to tables within a relational database, where each key corresponds to a singular value. While this analogy may appear enticing initially, it often leaves developers disheartened. They begin their work anticipating up to one message per unique key after diligently reviewing the documentation, only to grapple with a different reality later. And it hurts.
💡 It’s vital to note that the actual deletion of data transpires within inactive segments, contingent upon specific conditions. Numerous configuration parameters govern this process. The crucial point is that data persistence, even after compaction, endures considerably. This temporal aspect necessitates careful consideration in the formulation of your service design.
Tombstones
Now, let’s delve into another captivating aspect—compaction. When you publish a message with an existing key to a topic with compaction enabled, it’s akin to an UPDATE operation in a database. And if we have the power to make changes, we should also be able to remove them. To initiate a deletion, you send a message with the key and an empty body (essentially passing NULL instead of a body). This combination is aptly named a “tombstone,” akin to a null terminator in a record’s history.
These tombstones find their place within the topic, serving as markers for consumers (the services that read from Kafka). Once a consumer encounters a tombstone, it signifies that a record with the corresponding key has been deleted, prompting the consumer to process this revelation accordingly. Moreover, tombstones aren’t permanent fixtures; they have their lifespan determined by a separate configuration. It’s wise not to set this duration too short, particularly if you’re uncertain about the pace of your topic consumers. Should a tombstone be removed before slower consumers have had a chance to process it, the record it represents won’t be deleted for them. It’ll linger indefinitely.
On the surface, this process appears meticulously designed and well-documented, without any signs of trouble. We even devised a service that extracts the roster of current events from a topic and caches it in memory. With numerous sporting events, it’s inevitable that they eventually conclude and become candidates for deletion. Here, we employed the tombstone method in a topic configured with compaction.
💡 However, over time, we observed an unsettling trend—the startup time of our service instances was on the rise. In a nutshell, tombstones persisted indefinitely despite our correct configuration settings. There exists KIP-534, which should have addressed this issue already. However, we continued grappling with this bug since we still needed to update our Kafka version. Our workaround involved introducing an additional deletion policy to remove records after a specified period. We resorted to periodically injecting synthetic updates to prevent the loss of future events that lacked updates.
Offsets and Commits
As previously highlighted, Kafka deviates from the conventions of a typical message broker. While producers publish messages, and consumers read and possibly commit something, a crucial distinction can perplex newcomers. It’s common to encounter queries regarding how to re-read a message, how to delete it post-reading, how consumers can signal successful processing, or why the client receives the next message even when the preceding one hasn’t been committed. Part of this confusion arises because the familiar commit practices found in standard message brokers don’t necessarily apply to Kafka. These aren’t the familiar commits developers might be accustomed to.
To grasp this concept, envision a Kafka topic as a stream akin to a file or a memory buffer. Interacting with this stream involves opening it, specifying the reading position, and retrieving items sequentially. There’s no need to inform Kafka about a successful read. If a consumer fetches a message during the current call, the subsequent call will yield the next message.
Each message’s position is termed an “offset.” Consumers should specify the starting offset from which they wish to read. This can be defined in absolute and relative values, from the topic’s inception to its conclusion. Since most scenarios involve a service resuming reading from where it left off after a restart, the last read offset must be provided upon reconnection. Kafka offers a built-in feature to streamline this process.
Consumer groups facilitate this feature, essentially an assembly of consumers that collectively read a predefined set of topics. The topic partitions are distributed evenly among all consumers, ensuring that at any given time, only one consumer is engaged with any partition. While their primary purpose is horizontal scaling, we’ll concentrate on their ability to manage offsets. Once an offset for a specific topic/partition combination is stored, should that partition be reassigned to another consumer (due to a restart, scaling, or other factors), the new consumer resumes reading from the offset following the stored one.
This act of preserving offsets is referred to as committing. Importantly, it isn’t a confirmation of message read or processing completion; it’s merely a means of establishing a starting point for future consumers of that partition. It’s worth noting that a consumer can commit any offset, not solely the one it has just read.
Exactly Once Consumers
With this in mind, the frequency of commits may not align with the rate of message reception. In situations where the message load is substantial, committing after each message can severely negatively impact performance. In high-load systems, committing offsets less frequently, such as every few seconds, is more common.
This strategy, however, can lead to some messages being processed more than once. For instance, consider a scenario where a service restarts after processing message 10 but only manages to commit message 5. Consequently, upon restarting, it will re-read messages 6 to 10.
Developers must always be mindful of this and design their services to be idempotent, a rather complex term signifying that repeated execution of an operation should not bring about any changes. Some developers attempt to attain what’s known as “exactly-once semantics” (where a message is read only once) by tinkering with the frequency of commits and various Kafka settings, such as explicitly issuing a commit for each message.
💡 However, this approach significantly diminishes efficiency and doesn’t guarantee true exactly-once processing. Even if a message is successfully processed, if the service or infrastructure fails while the commit is being transmitted, it can result in the message being re-read after the service restarts.
Consumer Groups for Assign
One day, an unusual occurrence caught our attention—a sudden influx of enigmatic consumer groups infiltrating our Kafka cluster. Ordinarily, consumer groups sport meaningful names, providing insights into the associated service, product, or team, thereby aiding in identifying topic consumers. However, these peculiar groups lacked meaningful identifiers and were characterized solely by opaque GUIDs. The question loomed—where did they originate?
Consumer groups offer a potent mechanism for orchestrating the scaling of reading operations. Kafka adeptly handles the intricacies of partition redistribution among consumers when additions or removals are made to the group. Nevertheless, a manual approach is available for those who relish retaining granular control over operations.
By connecting via the Assign() method rather than Subscribe(), consumers are granted complete command over the situation, enabling them to specify which partitions they intend to read from. In such instances, consumer groups become superfluous. Yet, somewhat quirkily, you still need to designate one when creating a consumer, and this group invariably materializes within the cluster.
Unraveling the mystery behind these newfound enigmatic groups led us to a service employing Assign(). But the profusion of these groups and their GUID-based nomenclature raised questions. Why so many, and where did these GUIDs originate?
We soon uncovered the source of this enigma. In the case of a .NET client obtained from the official repository, a GUID was the group’s name. A unique identifier is mandatory in most scenarios featuring a GUID. Guided by the reflexes ingrained in any .NET developer, we reached for Guid.NewGuid(), a function that dutifully produces unique identifiers. Yet, it was precisely here that our problem lay. A new consumer group was born with each service restart, while the old ones lingered. This behavior struck us as rather peculiar and hardly “by design.”
However, an epiphany dawned during a deeper dive into consumer examples utilizing Assign()—they were not employing Guid.NewGuid(), but rather new Guid(). The latter yields not a unique GUID but a default value comprising all zeros. It became evident that the library samples employed the Guid type to obtain a constant, which served as the consumer group name. You can peruse these samples here.
💡 The key takeaway from this intriguing saga is that don’t hesitate to employ constants for consumer groups in all scenarios, whether using Subscribe() or Assign(). Don’t be swayed by the examples furnished by the library.
Client Libraries
Embarking on your Kafka journey with a good book (a commendable choice), you’ll likely encounter Java as the primary illustrative language, replete with its fascinating intricacies. For instance, you’ll delve into the consumer’s implementation of a rather sophisticated protocol that adeptly conceals numerous behind-the-scenes details like the inner workings of consumer groups, load balancing, and more.
Perhaps this prevalence of Java examples is why the landscape of Kafka client libraries appears relatively sparse, primarily featuring two stalwarts—the native JVM-based client and librdkafka, coded in C, which forms the bedrock for clients in various other programming languages. One noteworthy distinction lies in how they handle offset commits.
Java clients adopt an all-in-one-thread approach, bundling everything—message retrieval from Kafka, offset commits, transactions, and the like—within the poll() call. Because these actions unfold in a single thread, developers can rest assured that an offset commit promptly follows upon message retrieval. The offset remains unsaved in Kafka if the service encounters a mishap before the poll method is invoked. Consequently, upon service restoration, the same message is read once again.
On the flip side, librdkafka takes a divergent path. Here, offsets are committed in the background, managed by a dedicated thread. After invoking the Commit method, the offset may or may not successfully reach Kafka. Moreover, an offset could be committed under default configurations. Yet, the associated message may evade processing (for more detailed insights, refer to this resource). Thus, when employing librdkafka, it’s generally advisable to configure the following settings for optimal results in most scenarios.
Default Partitioners
Our primary technology stack revolves around .NET. However, at a certain juncture, we decided to infuse some variety—specifically, we introduced a dash of JVM into the mix, courtesy of Scala. Why, you might ask? Well, Kafka, our chosen platform, is predominantly crafted in Java and Scala, and the JVM offers an elevated API known as Kafka Streams. To draw a comparison, this API divergence is akin to the contrast between handling files in C versus Python.
In the former scenario, you grapple with the nuances of file opening and closure, buffer allocation and deal location, loops, and all the intricacies of low-level byte manipulation. It typically translates into dozens of lines of code. The same task is effortlessly achieved in the latter with a concise one-liner.
Within Kafka Streams, topics are introduced as streams—sources from which you can read, join with other streams (i.e., topics) based on a key, or succinctly apply predicates to filter messages per specific criteria.
So, we embarked on writing code and set it into motion, but alas, it didn’t yield the expected results. No errors, yet no outcomes either. This spurred us to delve deeper, and our explorations unearthed some intriguing revelations.
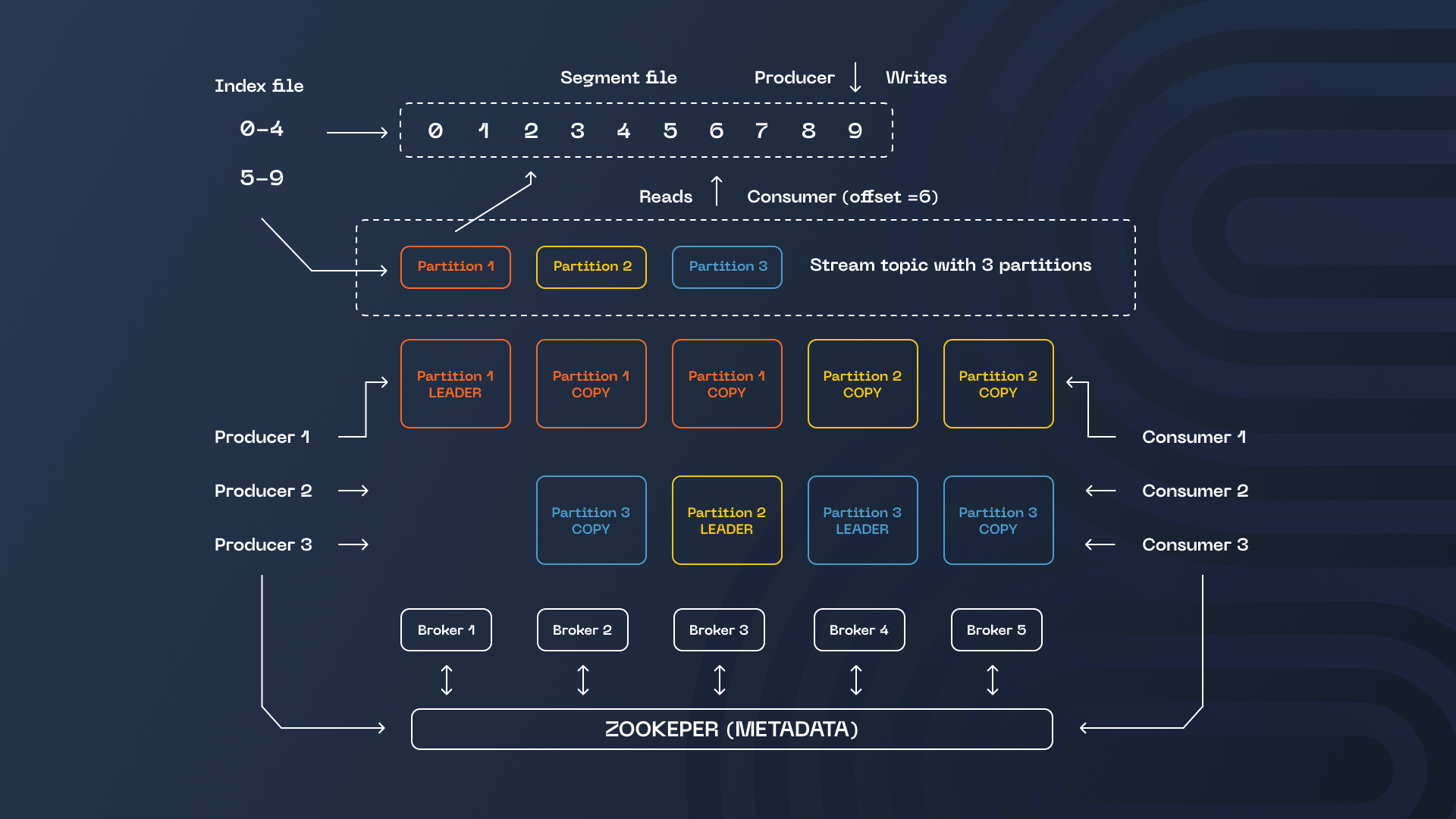
To grasp the significance of these discoveries, let’s delve into the Kafka concepts of keys and partitions. Messages in Kafka find their abode in topics, and these topics are partitioned. Each partition functions as a shard of sorts. A topic’s data is partitioned into discrete segments, each stashed on different brokers. This configuration bolsters the number of producers and consumers for that topic.
Novices often intermingle the notions of partitions (shards) and replicas (copies). The distinction lies in that a partition solely holds a portion of a topic’s data, while a replica contains the entirety. These two aspects can coexist; in most instances, topics encompass multiple partitions and replicas.
Partitions are instrumental in enhancing efficiency, whereas replicas bolster reliability and availability. Efficiency gains stem from the horizontal scaling of consumers. Adhering to the recommended approach with consumer groups, only one consumer can read from a partition at any time. Therefore, the scalability limit for reads aligns with the number of partitions. A consumer group may still comprise more consumers than there are partitions, but any surplus consumers remain idle.
The rationale behind partitioning is allocating data to specific partitions based on predetermined criteria. While a round-robin mechanism akin to conventional load balancing could dispatch messages to partitions, this approach must be revised for many commonplace scenarios where messages related to a single entity (e.g., modifications to an order) must be handled by the same consumer. A more pragmatic approach involves a hash function applied to the message key, determining the destination partition for the message.
Things begin to get intricate here, but kudos to the Kafka developers for simplifying matters. When dispatching a message, you are required to specify the partition. However, clients also incorporate a built-in helper mechanism that computes the appropriate partition.
This determination hinges on using what is known as a partitioner—an implementation of a hashing function, essentially. There exists a default partitioner that operates seamlessly, often allowing developers to remain blissfully unaware of its existence.
Returning to our problem, Scala and .NET clients employed different default partitioners. In our specific case, we had two services underpinned by distinct technologies contributing to the same topic. This discrepancy led to messages with identical keys ending up in different partitions.
💡 In scenarios where multiple services are tasked with writing to the same topic, it’s imperative to scrutinize the default partitioners in use. Consider system design patterns where a solitary service handles writing to a particular topic, thereby averting this potential issue.
Timestamps
Every message within Kafka comes equipped with a timestamp field. You might assume that the broker auto-populates this timestamp upon message insertion. However, it’s prudent not to place undue confidence in this assumption.
Primarily, Kafka offers the flexibility to set the timestamp explicitly. Additionally, it provides two distinct options for scenarios where the timestamp isn’t explicitly defined. You can use the timestamp recorded on the producer’s side (indicating when the message was sent) or rely on the broker’s timestamp (signifying when the message was added to the topic).
Hence, exercising caution regarding the reliance on Kafka tool message timestamps is advisable, particularly when you lack control over the producer of the topic. In such cases, a safer approach involves routing the messages to your designated topic and setting the timestamps per your specific requirements.
Zookeeper vs. Kafka
Why Kafka? Kafka, with its inception dating back to 2011, is undeniably a seasoned and mature product. Certain APIs have changed their evolution, and some have even been rendered obsolete.
Take, for instance, the initial approach to establishing connections, where the Zookeeper address was a prerequisite component, especially in Kafka versions predating 2.8.0. Subsequently, the paradigm shifted towards employing the addresses of Kafka brokers (the bootstrap servers mentioned earlier). Presently, the recommended method is utilizing bootstrap servers for connections. However, it’s worth noting that connection via Zookeeper still functions and maintains support in certain utilities.
We encountered an intriguing scenario where a consumer group had ostensibly been removed, but its metrics continued to be published. The root cause was traced to the fact that the group’s removal had been orchestrated using a tool configured with a Zookeeper connection. Conversely, the metrics were being gathered by an exporter linked via bootstrap servers. Consequently, the group persisted unscathed despite the tool signaling success for the removal request.
💡 In summation, it’s imperative to avoid using outdated protocols or, at the very least, abstain from mixing them with newer ones.